HowTo:使用 TensorFlow Inception V3 訓練影像辨識模型、生成推論引擎
深度學習分為兩階段:訓練與推論,前者需對大量的資料數據進行無數次的計算,訓練並產生模型;而後者則是將模型對外提供辨識服務。
模型訓練需要大量的運算資源,才能取得辨識效果良好的模型,TWCC 提供您容器解決方案,使用 GPU 資源運算,可快速生成模型。
本文將一步步教學如何透過 TWSC 開發型容器,使用 GPU 資源[1][2],並搭配預設儲存系統–高速檔案系統 (HFS) 作為訓練資料與模型之存取空間,利用 TensorFlow Inception V3 卷積類神經網路架構、CIFAR-10 資料集 進行貓、狗影像辨識模型訓練,並生成推論引擎、對外提供圖片辨識服務。
信息
- [1] 可建立最多含 8 GPUs 的容器,請參考規格與定價。
- [2] 若需使用 8 GPUs 以上的資源,您可以使用 TWSC 台灣杉二號 (命令列介面)服務來完成工作。
Part 1. 影像辨識模型訓練
Step 1. 登入 TWSC
若尚無帳號,請參考 註冊 TWSC 帳號。
Step 2. 建立開發型容器
請參考 開發型容器 並依據下方設定,於 TWCC 建立開發型容器:
映像檔類型: TensorFlow
映像檔版本: tensorflow-23.05-tf2-py3:latest
基本設定: 型號 c.super
Step 3. 連線容器、下載訓練程式
- 參考 連線容器,使用 Jupyter Notebook 或 SSH 連線進入容器之預設儲存空間
輸入以下指令,將 TWCC GitHub Inception v3 影像模型訓練的架構程式,下載至容器
git clone https://github.com/TWCC/AI-Services.git
Step 4. 進行 AI 模型訓練
進入 「Tutorial_Three」目錄
cd AI-Services/Tutorial_Three執行模型訓練
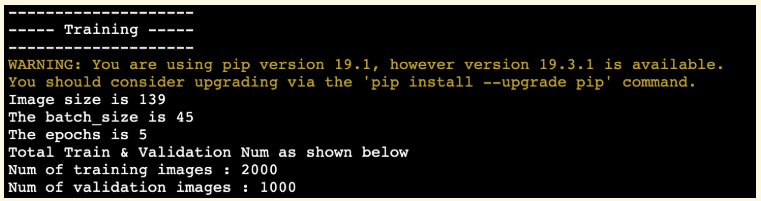
bash V3_training.sh --path ./cifar-10-python.tar.gz在 Terminal 看到以下訊息,表示即將開始訓練模型
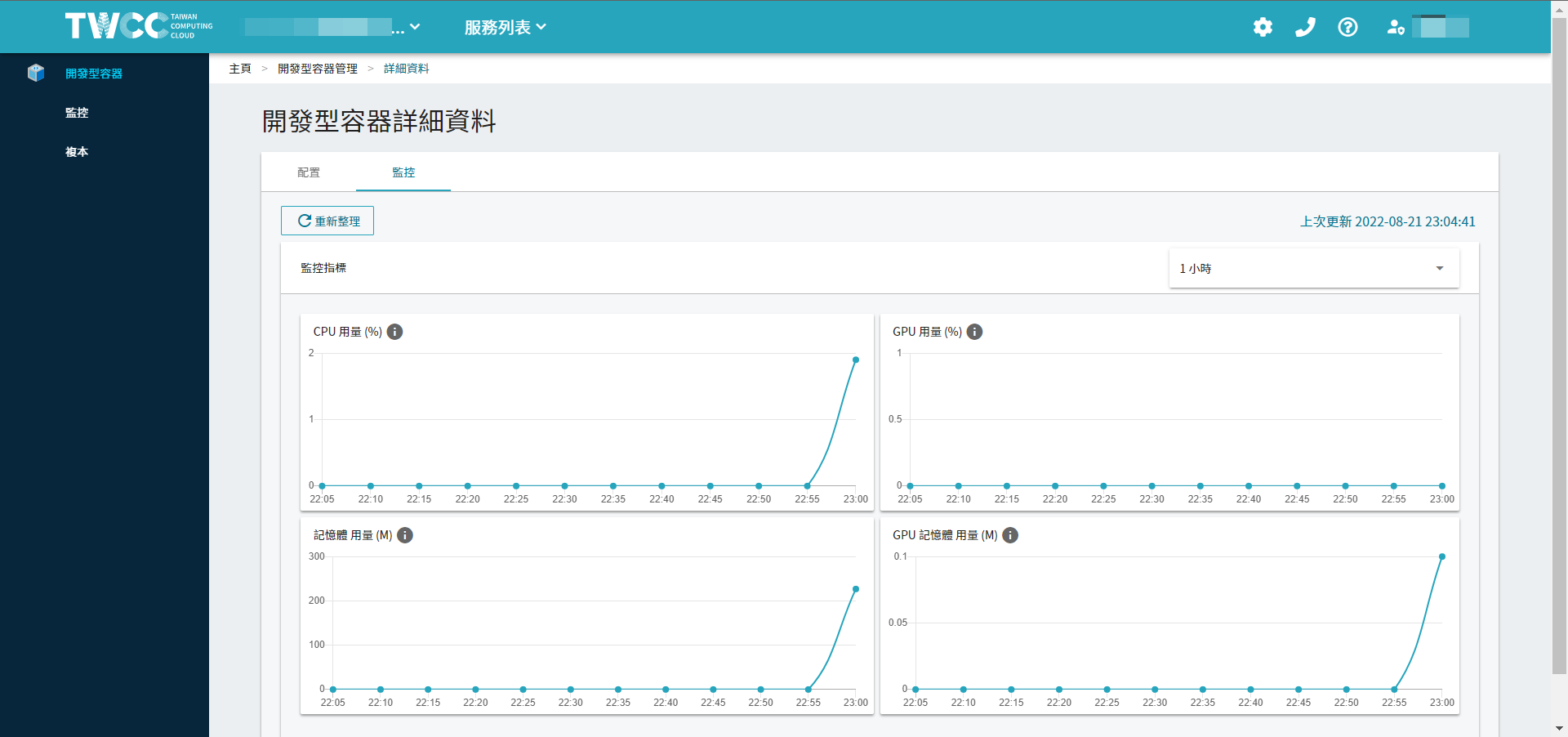
- 在訓練過程中,可在「開發型容器詳細資料」頁面可檢視 CPU/GPU、記憶體與網路的資源使用狀況
- 模型訓練完成,將會存放在路徑:
AI-Services/Tutorial_Three/inceptionv3/train/weights

Part 2. 生成推論辨識引擎
以下教學如何將訓練好的模型,生成推論引擎,並對外提供圖片推論、辨識的網頁服務。
Step 1. 連線容器
請再次 連線進入容器
Step 2. 生成推論辨識引擎
- 進入 Tutorial_Three 目錄
cd AI-Services/Tutorial_Three
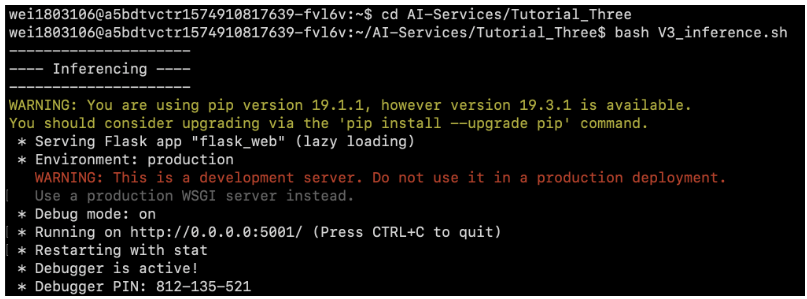
- 開啟 AI 推論引擎的服務
bash V3_inference.sh
Step 3. 圖片辨識網站
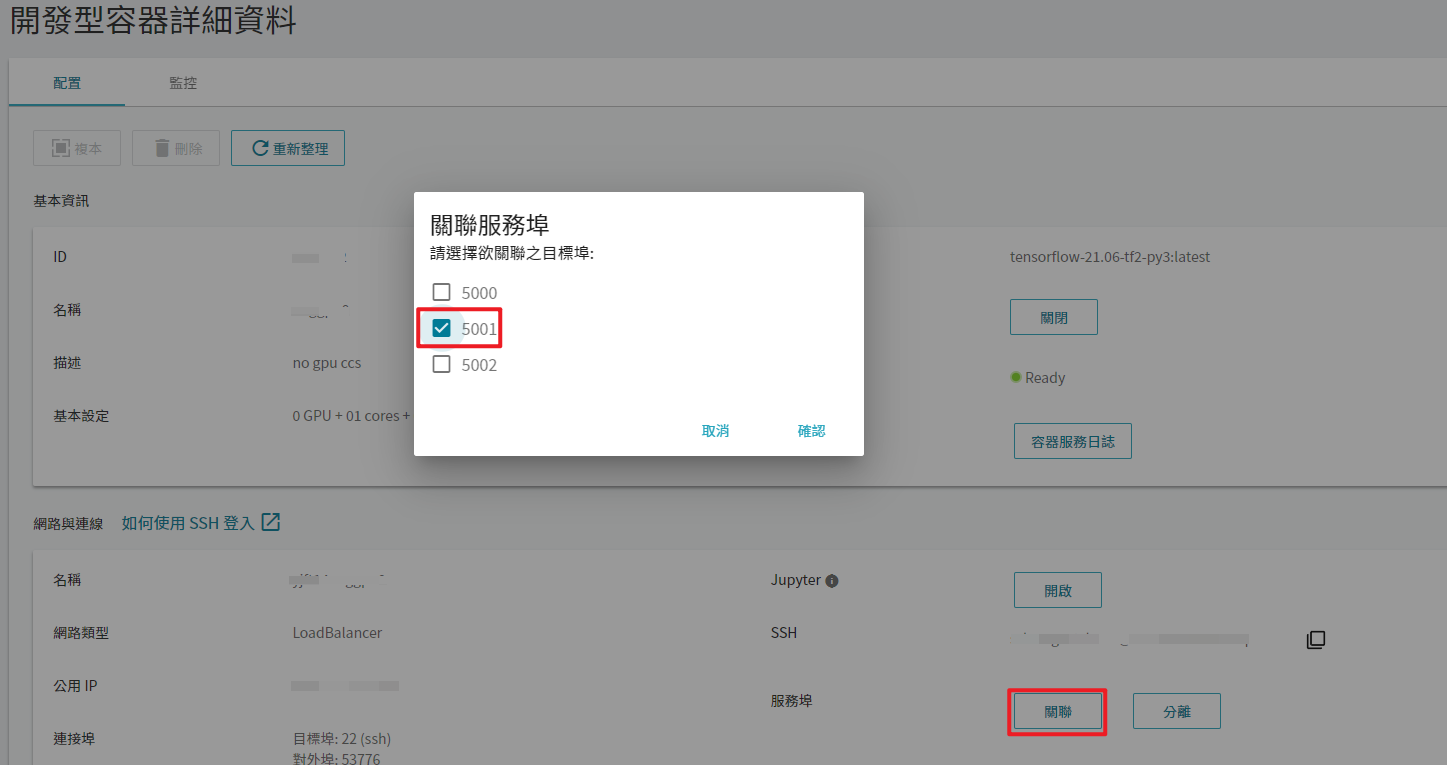
- 請先至開發型容器詳細資料頁 ➡️ 點選「關聯」服務埠 ➡️ 勾選「5001」 ➡️ 再按下確定便可開啟 HTTP 網頁服務端點
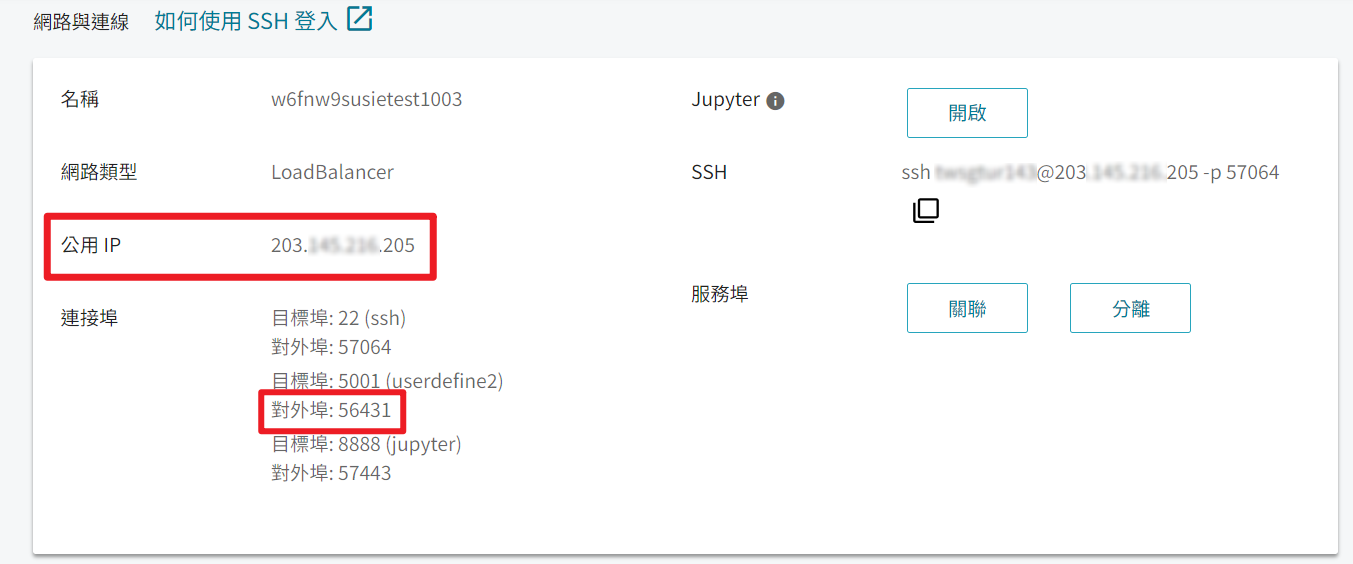
- 開啟瀏覽器 ➡️ 在網址列輸入
容器公用IP:對外埠(如下,可於容器詳細資料頁查詢) 便可開始使用 AI Inference 的服務
- 點選「選擇檔案」選擇要進行辨識內容的圖片檔案,並點選「Upload」上傳圖片

- 以貓咪圖片作為測試範例,圖片辨識的結果與相似度數值顯示在瀏覽器,與 Egyptian_cat (0.4873894) 最為相似

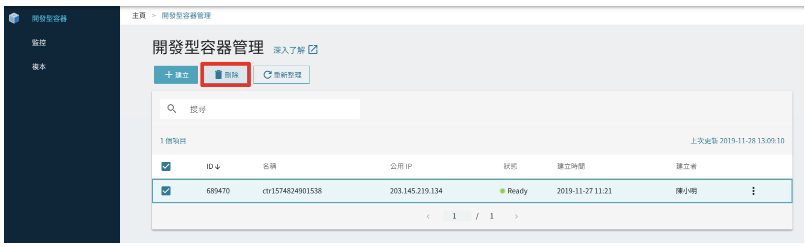
Step 4. 刪除容器,回收資源
容器建立後即持續計費,若不再需要執行訓練與推論,您可以從 TWCC 「開發型容器管理」頁,勾選容器、點選「刪除」,回收資源並停止計費。