Vision Language Model API and parameters
The English version of this document is under construction and will be available soon.
視覺語言模型(Vision Language Models, VLMs)是一種先進的人工智慧技術,結合了電腦視覺與自然語言處理的能力,能同時處理並理解圖像和文字資料。這類模型是人工智慧領域的一項重要突破,為多模態的理解與生成任務帶來了強大的解決方案,展現出廣泛的應用潛力。
- Llama3.2-FFM-11B-V-32K
圖片支援格式
AFS 視覺語言模型推論服務支援以下圖片格式:
- PNG
- JPG \ JPEG
- WebP
- GIF (只支援靜態圖片)
圖片轉換為 Token 的計算方式
圖片計算的最小單位是 560x560 像素,每個單位為 1601 Token 量,圖片尺寸最多可達四個單位。
系統會將上傳的圖片自動進行等比例放大或縮小,讓圖片尺寸符合四個單位的範圍之內,放大或縮小過程中系統會保持圖片的原始的寬高比,不會將圖片裁剪或變形。
等比例放大或縮小後的圖片會依據以下最符合的標準尺寸來計算 Token 量:
| 寬度(像素) | 高度(像素) | 單位數 | Token 量 |
|---|---|---|---|
| 560 | 560 | 1 | 1601 |
| 560 | 1120 | 2 | 3202 |
| 560 | 1680 | 3 | 4803 |
| 560 | 2240 | 4 | 6404 |
| 1120 | 1120 | 4 | 6404 |
| 2240 | 560 | 4 | 6404 |
| 1680 | 560 | 3 | 4803 |
| 1120 | 560 | 2 | 3202 |
範例一:圖片尺寸為 200 x 280,則寬高分別放大 2 倍成為 400 x 560,屬於 560 x 560 組合,計算一個單位的 Token 量。
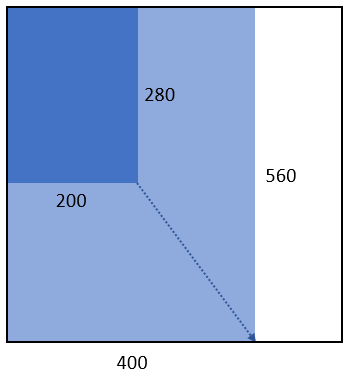
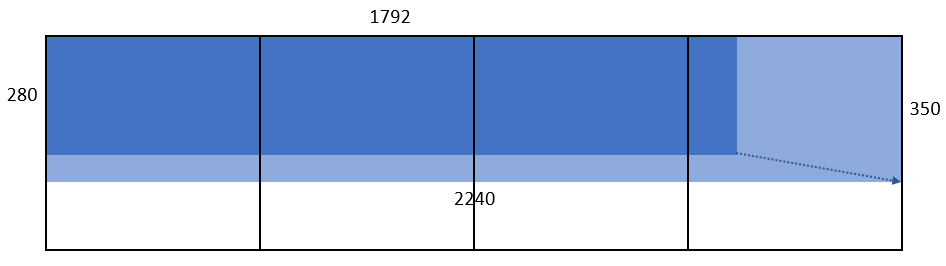
範例二:所傳入的圖片尺寸為 1792 x 280,則寬高分別放大 1.25 倍成為 2240 x 350,屬於 2240 x 560 組合,計算四個單位的 Token 量。
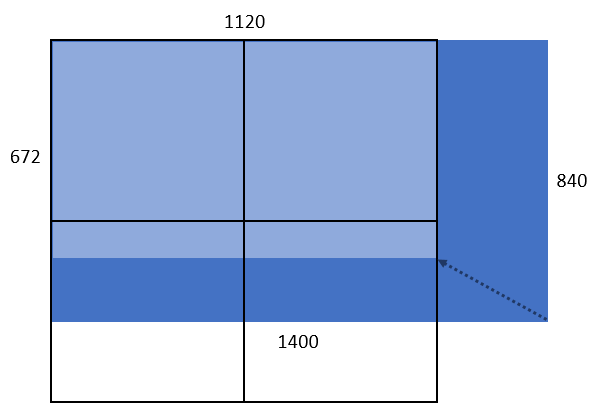
範例三:所傳入的圖片大小為 840 x 1400,則寬高分別縮小 1.25 倍成為 672 x 1120,屬於 1120 x 1120 組合,計算四個單位的 Token 量。
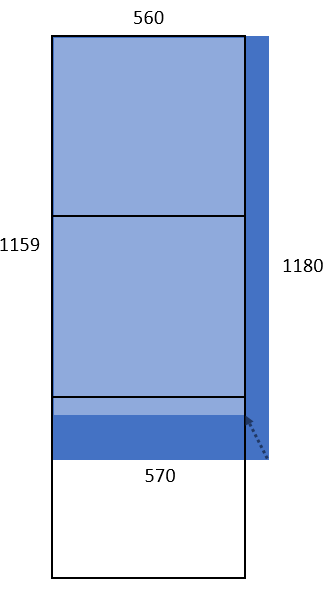
範例四:所傳入的圖片大小為 570 x 1180,則寬高分別縮小約 1.0178 倍成為 560 x 1159,屬於 560 x 1680 組合,計算三個單位的 Token 量。
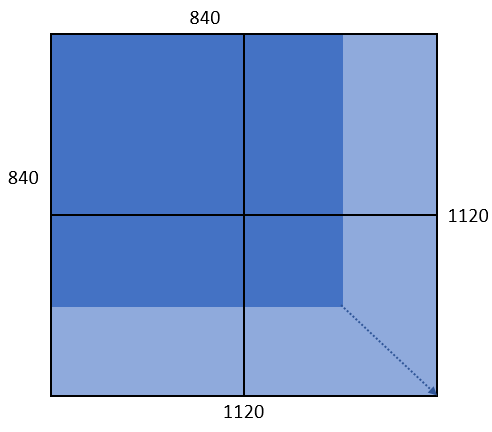
範例五:所傳入的圖片大小為 840 x 840,因為原圖即為四個單位,則寬高分別放大約 1.33 倍成為 1120 x 1120,屬於 1120 x 1120 組合,計算四個單位的 Token 量。
使用方式
AFS 視覺語言模型推論服務可以分別利用兩種方式傳入圖檔資訊。
- 填入欲理解圖檔的 URL
- 將圖檔轉換成 base64 編碼的格式傳入
傳入圖檔 URL
範例圖片的 URL 可能會受限於企業內的防火牆機制或其他保護機制而無法讀取,若碰到此類問題,建議請利用 base64 編碼的機制。
from openai import OpenAI
import os
API_KEY = {API_KEY}
API_URL = "https://api-ams.twcc.ai/api"
BASE_URL = f"{API_URL}/models"
MODEL_NAME = "llama3.2-ffm-11b-v-32k-chat"
SAMPLE_IMAGE_URL = "https://tws.twcc.ai/wp-content/uploads/2022/01/about-bg_1.jpg"
client = OpenAI(
api_key=API_KEY,
base_url=BASE_URL
)
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": SAMPLE_IMAGE_URL
}
},
{
"type": "text",
"text": "這張圖裡面有什麼?"
}
]
}
]
response = client.chat.completions.create(
model=MODEL_NAME,
temperature = 0.1,
max_tokens = 3600,
top_p = 0.5,
messages = messages
)
print(f"輸出: {response.choices[0].message.content}")
返回結果:
若希望返回結果可以更多樣化,請調高 temperature 和 top_p 這兩個參數值。
基於 Base64 格式
請將以下範例程式中的圖片檔案路徑,替換成本地的圖片路徑。
from openai import OpenAI
import base64
API_KEY = {API_KEY}
API_URL = "https://api-ams.twcc.ai/api"
BASE_URL = f"{API_URL}/models"
MODEL_NAME = "llama3.2-ffm-11b-v-32k-chat"
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
IMAGE_PATH = "./your_sample_image.jpg"
BASE64_IMAGE = f"data:image/jpeg;base64,{encode_image(IMAGE_PATH)}"
client = OpenAI(
api_key=API_KEY,
base_url=BASE_URL
)
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": BASE64_IMAGE
}
},
{
"type": "text",
"text": "這張圖裡面有什麼?"
}
]
}
]
response = client.chat.completions.create(
model=MODEL_NAME,
temperature = 0.1,
max_tokens = 3600,
top_p = 0.5,
messages = messages
)
print(f"輸出: {response.choices[0].message.content}")
透過 curl 呼叫推論服務 API
使用者也可以透過 curl 工具直接呼叫推論服務。範例程式的最後,有透過 json_pp 工具,讓輸出結果容易閱讀,可根據使用者情境需要,動態取消。
curl --location '{API_URL}/models/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer {API_KEY}' \
--data '{
"model": "llama3.2-ffm-11b-v-32k-chat",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "這張圖裡面有什麼?"
},
{
"type": "image_url",
"image_url": {
"url": "https://tws.twcc.ai/wp-content/uploads/2022/01/about-bg_1.jpg"
}
}
]
}
],
"temperature": 0.1,
"max_tokens": 3600,
"top_p": 0.5
}' | json_pp
返回結果:
{
"choices" : [
{
"finish_reason" : "stop",
"index" : 0,
"logprobs" : null,
"message" : {
"content" : "這張圖片顯示的是一排大型的電腦機櫃,機櫃上標有“TAIWANIA 2”的標誌,可能是某種高性能計算機或數據中心設備。",
"role" : "assistant",
"tool_calls" : null
}
}
],
"created" : 1736486977,
"id" : "chatcmpl-DqJjZMAJ4tLkZwirzyz3DVtD",
"model" : "llama3.2-ffm-11b-v-32k-chat",
"object" : "chat.completion",
"system_fingerprint" : null,
"usage" : {
"completion_tokens" : 52,
"completion_tokens_details" : null,
"prompt_tokens" : 6424,
"prompt_tokens_details" : null,
"total_tokens" : 6476
}
}
多輪對話
AFS 視覺語言模型推論服務也可以進行多輪對話。
from openai import OpenAI
import os
API_KEY = {API_KEY}
API_URL = "https://api-ams.twcc.ai/api"
BASE_URL = f"{API_URL}/models"
MODEL_NAME = "llama3.2-ffm-11b-v-32k-chat"
SAMPLE_IMAGE_URL = "https://tws.twcc.ai/wp-content/uploads/2022/01/about-bg_1.jpg"
client = OpenAI(
api_key=API_KEY,
base_url=BASE_URL
)
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": SAMPLE_IMAGE_URL
}
},
{
"type": "text",
"text": "這張圖裡面有什麼?"
}
]
}
]
response = client.chat.completions.create(
model=MODEL_NAME,
temperature = 0.1,
max_tokens = 3600,
top_p = 0.5,
messages = messages
)
print(f"第一輪輸出:{response.choices[0].message.content}")
messages.append({
"role": "assistant",
"content": response.choices[0].message.content
})
messages.append({
"role": "user",
"content": [
{
"type": "text",
"text": "請用古詩詞來描述這個場景"
}
]
})
response = client.chat.completions.create(
model=MODEL_NAME,
temperature = 1,
max_tokens = 3600,
top_p = 0.9,
messages = messages
)
print(f"第二輪輸出:{response.choices[0].message.content}")
返回結果:
第二輪輸出:黑夜中,數位之聲,屏幕上燈火通明,數位之影,搖曳不定,數位之光,照耀在黑暗中,數位之聲,聆聽著人類的希望。
本範列程式為了讓第二輪輸出更多樣化,所以調高 temperature 和 top_p 這兩個參數值,使用者所見到的結果可能會和本文所描述有所不同。
Stream 模式
透過 stream 參數設定為 True,可以讓輸出結果的反應更即時。
在 Stream 模式下,使用者可以看到動畫般的輸出效果。
from openai import OpenAI
import os
API_KEY = {API_KEY}
API_URL = "https://api-ams.twcc.ai/api"
BASE_URL = f"{API_URL}/models"
MODEL_NAME = "llama3.2-ffm-11b-v-32k-chat"
SAMPLE_IMAGE_URL = "https://tws.twcc.ai/wp-content/uploads/2022/01/about-bg_1.jpg"
client = OpenAI(
api_key=API_KEY,
base_url=BASE_URL
)
messages = [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": SAMPLE_IMAGE_URL
}
},
{
"type": "text",
"text": "這張圖裡面有什麼?"
}
]
}
]
response = client.chat.completions.create(
model=MODEL_NAME,
temperature = 0.1,
max_tokens = 3600,
top_p = 0.5,
messages = messages,
stream = True
)
print("Stream 輸出:")
for chunk in response:
if len(chunk.choices) > 0:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end='', flush=True)