API 取得所需資訊及參數說明
取得所需資訊
AFS ModelSpace 公用模式(Public Mode)
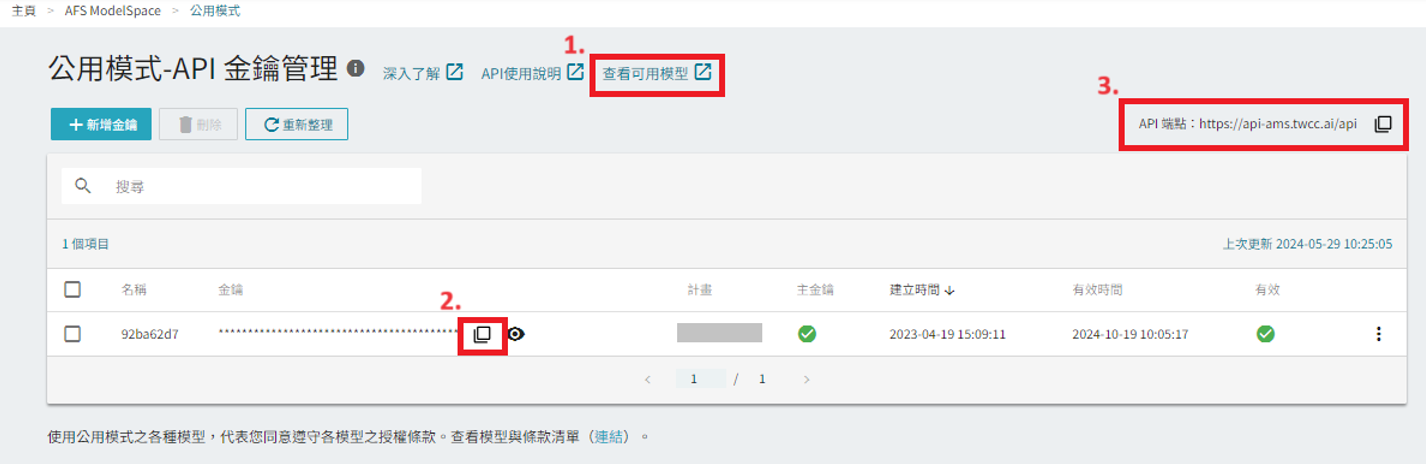
MODEL_NAME:請參考模型名稱對照表API_KEY:請從 公用模式 - API 金鑰管理 頁面的列表中複製取得API URL:請從 AFS ModelSpace 的 公用模式 - API 金鑰管理 頁面中的右上角複製
AFS ModelSpace 私有模式(Private Mode)
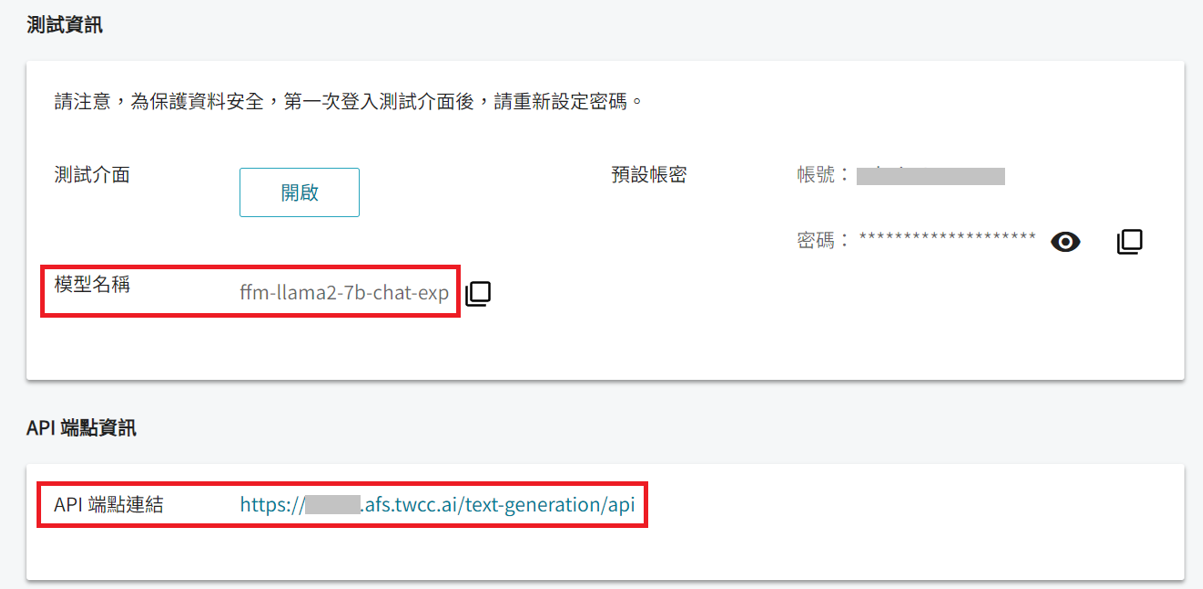
MODEL_NAME: 如上圖,可從該服務的詳細資料頁面中模型名稱複製。API_URL:如上圖,可從該服務的詳細資料頁面中 API 端點連結複製。API_KEY: 登入該服務的測試介面後點選右上角的帳號資訊,即可看到 API 金鑰。
AFS Cloud
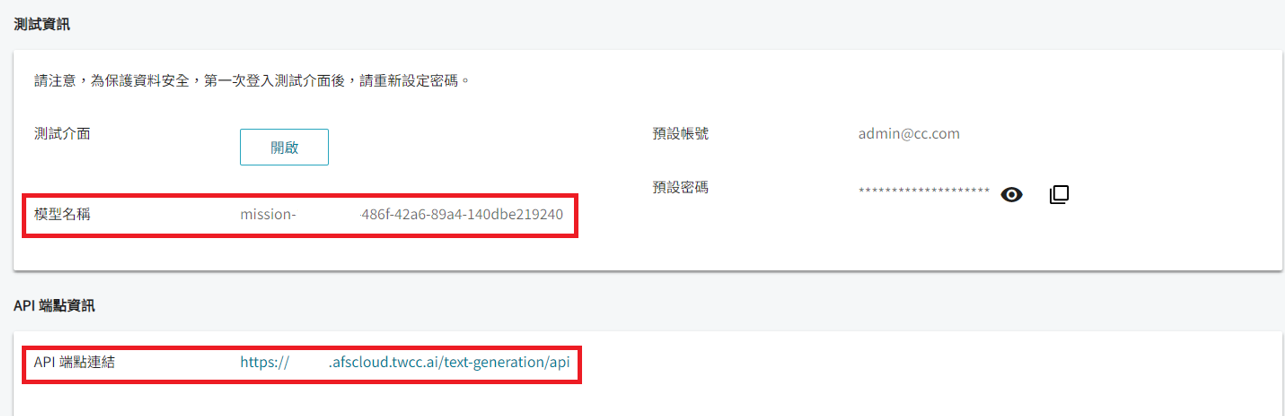
MODEL_NAME: 如上圖,可從該服務的詳細資料頁面中模型名稱複製。API_URL:如上圖,可從該服務的詳細資料頁面中 API 端點連結複製。API_KEY: 登入該服務的測試介面後點選右上角的帳號資訊,即可看到 API 金鑰。
參數說明
Request 參數
max_new_tokens:一次最多可生成的 token 數量。- 預設值:350
- 範圍限制:大於 0 的整數值
使用限制
每個模型都有 input + output token 小於某個值的限制,如果輸入字串加上預計生成文字的 token 數量大於該值則會產生錯誤。
- Mistral (7B) / Mixtral (8x7B) : 32768 tokens
- Llama3 (8B 、 70B) : 8192 tokens
- Llama2-v2 (7B 、13B 、 70B) / Llama2 (7B 、13B 、 70B) / Taide-LX (7B) : 4096 tokens
- CodeLlama (7B 、 13B 、34B) : 8192 tokens
temperature:生成創造力,生成文本的隨機和多樣性。值越大,文本更具創意和多樣性;值越小,則較保守、接近模型所訓練的文本。- 預設值:1.0
- 範圍限制:大於 0 的小數值
top_p:當候選 token 的累計機率達到或超過此值時,就會停止選擇更多的候選 token。值越大,生成的文本越多樣化;值越小,生成的文本越保守。- 預設值:1.0
- 範圍限制:大於 0 且小於等於 1 的小數值
top_k:限制模型只從具有最高概率的 K 個 token 中進行選擇。值越大,生成文本越多樣化;值越小,生成的文本越保守。- 預設值:50
- 範圍限制:大於等於 1 且小於等於 100 的整數值
frequence_penalty:重複懲罰,控制重複生成 token 的概率。值越大,重複 token 出現次數將降低。- 預設值:1.0
- 範圍限制: 大於 0 的小數值
stop_sequences:當文字生成內容遇到以下序列即停止,而輸出內容不會納入序列。- 預設值:無
- 範圍限制:最多四組,例如 ["stop", "end"]
seed:亂數種子,具有相同種子與參數的重複請求會傳回相同結果。若設成 null,表示隨機。- 預設值:隨機 (原預設值為 42,現修正為隨機)
- 範圍限制:可設為 null,以及大於等於 0 的整數值
Request 參數調校建議
temperature的調整影響回答的創意性。- 單一/非自創的回答,建議調低 temperature 至 0.1~0.2。
- 多元/高創意的回答,建議調高 temperature 至 1。
- 若上述調整後仍想再微調
top-k和top-p,請先調整top-k,最後再更動top-p。 - 當回答中有高重複的 token,重複懲罰數值
frequence_penalty建議調至 1.03,最高 1.2,再更高會有較差的效果。
Response 參數
function_call:若有調用 Function,則模型會回覆呼叫函式與參數。details:針對特定需求所提供的細節資訊。total_time_taken:本次 API 的總花費秒數。prompt_tokens:本次 API 的 Prompt Token 數量(Input Tokens),會包含 system 預設指令、歷史對話中 user / assistant 的內容以及本次的問題或輸入內容的總 Token 數。generated_tokens: 本次 API 的 Generated Token 數量(Output Tokens),即為本次模型的回覆內容總 Token 數,而此 Token 數量越大,對應的總花費秒數也會隨之增長。(若有輸出大量 token 文字的需求,請務必優先採用 Stream 模式,以免遇到 Timeout 的情形。)total_tokens:本次 API 的 Total Token 數量 (Input + Output Tokens)。finish_reason:本次 API 的結束原因說明,例如 "stop_sequence" 代表模型已生成完畢,"function_call" 代表呼叫函式已生成完畢。("stop_sequence" 現已取代 "eos_token")